@肖哲等:《现代汉语同音字家族属性的计量研究》
本篇运用了较多统计分析方法。可以学习数据分析方法的使用、数据结果的分析过程。重在如何从数据中得出结论。
【摘要】
- 研究基于《现代汉语词典》和《现代汉语频率词典》,从类型频率与使用频率角度分析同音字家族属性。
- 主要发现:
- 单音节平均同音字密度为7.71(中等密度),平均使用频率为1354.91(高频属性)。
- 类型频率与使用频率的分布形成互补格局,均服从幂律分布。
- 同音字家族在类型多样化与使用经济性上实现平衡。
关键词:同音字家族、同音字密度、幂律分布、使用频率
【引言】
- 同音字现象对汉字认知、学习及信息处理有重要影响。
- 已有研究多关注整体同音率或同音度,缺乏音节家族层次的精细分析。
- 本文聚焦音节水平的同音字家族属性,结合基于密度的家族类型(小密度、中密度、大密度)与使用频率角度的家族类型(低频、中频、高频)展开计量研究。
【研究方法】
1. 数据库建立
- 语料来源:
- 《现代汉语词典(第7版)》:收录1340个单音节同音字家族,含10333个汉字。
- 《现代汉语频率词典》:补充汉字使用频率数据,未收录的极低频字默认频率为1。
- 数据处理:
- 排除繁体字、异体字,保留轻声音节。
- 多音字人工校对字频,总使用频率为1,815,583次。
2. 统计方法
- 类型频率:同音字家族成员数(同音字密度)。
- 使用频率:家族成员字频之和。
- 家族类型划分:基于频谱拐点与聚类分析(DBSCAN),区分密度与频率类型。
1. 基于频谱拐点的划分
-
步骤:
- 绘制分布频谱:以类型频率或使用频率为横轴,家族数为纵轴生成分布曲线。
- 识别拐点:
- 视觉观察:通过曲线斜率变化确定拐点(如家族数骤降后趋于平缓)。
- 数学辅助:计算相邻点的级差(家族数差值),级差显著变化的点视为拐点。
- 分类依据:
- 拐点将分布划分为不同区间,对应不同家族类型(如小、中、大密度)。
- 例如,类型频率拐点为3、12、26,对应四类密度家族。
-
示例(类型频率):
- 拐点1(类型频率=3):左侧家族数骤减(225→132),右侧平缓下降。
- 拐点2(类型频率=12):右侧家族数进入更低波动区间。
- 拐点3(类型频率=26):右侧家族数极低且波动微小。
2. DBSCAN聚类分析
- 基本参数:
- 家族数及占比
- 家族成员数及占比
- 家族总使用频率及占比
- 极高频成员数及占比
- 极高频成员使用频率及占比
- 参数选择:
- eps(邻域半径)
- min_samples(最小样本数)
- 分步聚类过程:
- 第一轮:识别超大密度家族
- 第二轮:在剩余数据中识别大密度家族
- 第三轮:区分中密度和小密度家族
- 每轮聚类的操作:
- 对当前数据进行DBSCAN聚类
- 分析聚类结果,确定分界线
- 分离出该类家族,保留剩余数据进行下一轮聚类
- 优势:
- 由于本文中无论类型频率还是使用频率均表现出非线性的特点(幂律分布),所含极端值较多。因此,相对于K均值聚类等易受极端值影响的方法,DBSCAN较适用于本文的数据。
DBSCAN聚类分析的核心原理💡
- 基本概念
- 基于密度:通过识别数据集中高密度区域(簇)与低密度区域(噪声)进行聚类。
- 参数依赖:需要设定两个参数:
eps(邻域半径)和minPts(核心点的最小邻居数)。 - 核心点:若某点的
eps邻域内至少有minPts个点,则为核心点。 - 簇扩展:从核心点出发,通过密度可达的点逐步扩展形成簇。
- 优势
- 无需预设簇数量,适合探索性分析。
- 能处理任意形状的簇(如线性、环形)。
- 自动识别噪声点(稀疏区域数据)
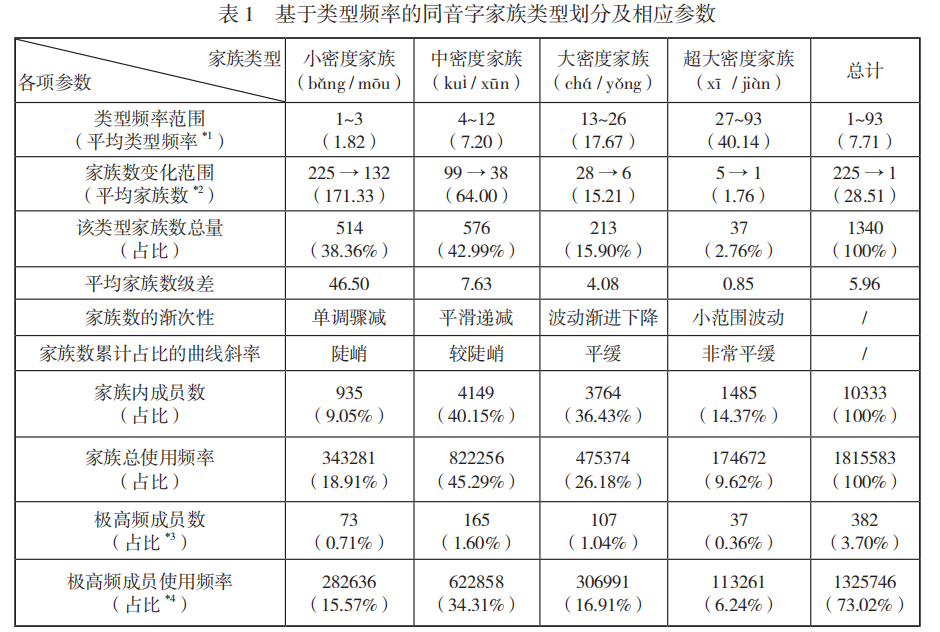
【研究结果1:基于类型频率的同音字家族分布】
1. 总体分布
- 类型频率分布服从幂律(
, )。 - 平均同音字密度为7.71,划分为四类:
- 小密度家族(1-3成员,占比38.36%)
- 中密度家族(4-12成员,占比42.99%)
- 大密度家族(13-26成员,占比15.90%)
- 超大密度家族(27-93成员,占比2.76%)
幂律分布(Power Law Distribution)💡
- 什么是幂律分布?
- 幂律分布描述的是一种特殊的数学关系,其中一个量的变化与另一个量的某次方成正比。
- 用数学公式表示就是:y = ax^b,其中a和b是常数。
- 生活中的例子
- 城市人口分布:少数大城市人口非常多,大多数城市人口较少
- 财富分布:少数人拥有大量财富,大多数人拥有较少财富
- 网站访问量:少数网站访问量极高,大多数网站访问量较低
Link to 二八法则
2. 分布特征
- 研究者对三种分布进行了卡方检验(χ²检验):
- 家族数分布 vs 家族成员数分布
- 家族数分布 vs 使用频率分布
- 家族成员数分布 vs 使用频率分布
- 结果显示这三种分布都有显著差异(p<0.01)
- 说明这三种分布方式是相对独立的,不会互相决定
- 极高频成员的分布:
- 极高频成员分布及使用频率分布
- 不服从家族数量分布
- 不服从家族成员数分布
- 通过Spearman相关分析发现:
- 家族成员数与极高频成员数的相关性很低(r=0.26)
- 家族成员数与极高频成员使用频率的相关性也很低(r=0.25)
- 举例说明:
- "fǎn"家族只有2个成员,但有一个高频字"反"
- "bì"家族有68个成员,但也只有一个高频字"必"
- 极高频成员分布及使用频率分布
- 卡方检验告诉我们:分布形态不同Spearman相关分析告诉我们:两个变量几乎没有相关性
- 三个主要发现
- 同音字密度水平:
- 总体平均密度是7.71
- 接近中密度家族的均值7.20
- 通过置换检验证明这个差异不显著
- (置换检验的结果(p=0.09)说明中密度家族的平均密度与总体平均密度没有显著差异,这就统计学地证明了现代汉语的同音字密度确实属于中等水平。这个结论比简单地比较平均值更有说服力,因为它考虑了随机波动的可能性。)
- 结论:汉语同音字密度属于中等水平
- 家族分布的互补性:
- 家族数量方面:
- 小密度家族(38.36%)
- 中密度家族(42.99%)
- 两者合计占81.34%
- 但从成员数量看:
- 中密度家族(40.15%)
- 大密度家族(36.43%)
- 超大密度家族(14.37%)
- 三者合计占90.95%
- 这说明虽然小密度家族数量多,但实际包含的字却很少
- 家族数量方面:
- 极高频字分布的随机性:
- 高频字出现在各种类型的家族中
- 不是家族成员越多就一定有更多高频字
- 家族大小与其中高频字的数量关系不大
- 同音字密度水平:
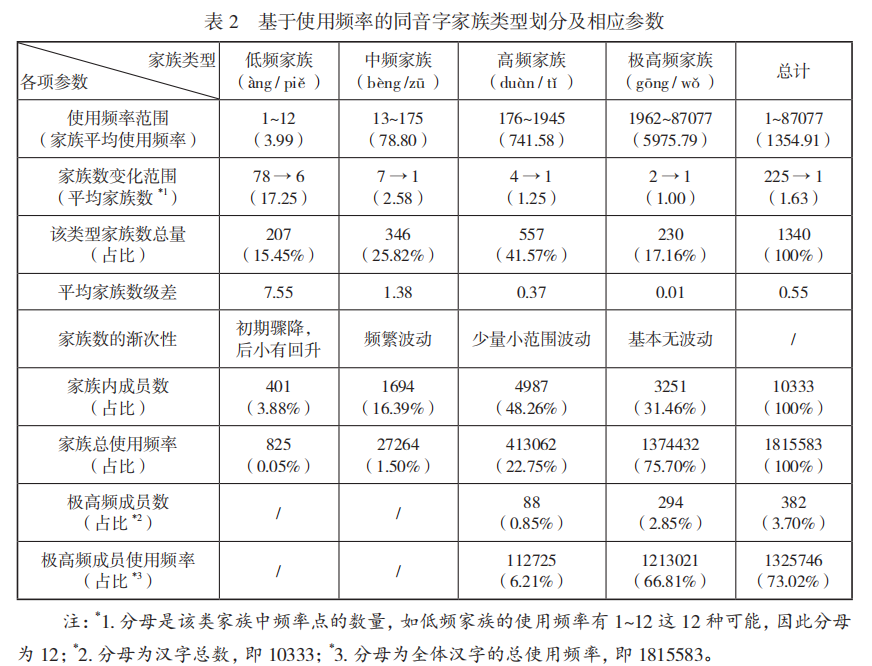
【研究结果2:基于使用频率的同音字家族分布】
1. 总体分布
- 使用频率分布服从幂律(
, )。 - 平均使用频率1354.91,划分为四类:
- 低频家族(1-12,占比15.45%)
- 中频家族(13-175,占比25.82%)
- 高频家族(176-1945,占比41.57%)
- 极高频家族(1962-87077,占比17.16%)
2. 分布特征
- 统计检验结果显示:
- 家族数分布、家族成员数分布和使用频率分布之间存在显著差异,说明它们具有独立性(方差分析)
- 家族成员数和使用频率之间存在中等程度的正相关(r=0.56)(Spearman 相关分析)
- 极高频成员主要分布在高频和极高频家族中,且大多数家族(256/312)只含1个极高频成员
- 家族使用频率的三个主要特征:
- 总体使用频率高:平均使用频率为1354.91,介于高频和极高频家族之间
- 分布呈互补性:低频/中频家族占41.27%,但高频/极高频家族贡献了98.45%的使用频率
- 极高频成员分布有规律:仅出现在高频和极高频家族中
【讨论】
一、现代汉语的平均同音字密度:中等密度
- 密度数值及可靠性:
- 平均同音字密度为7.71(每个音节平均拥有7.71个汉字)
- 与前人研究结果相近:
- 尹文刚(2003):7.85
- 苏新春和林进展(2006):8.31
- 密度属性定性:
- 确定为"中等密度"
- 基于四种家族类型分析
- 接近中密度家族平均值7.20
- 同音率概念的局限性:
- 同音率(72%-80.49%)仅为理论计算
- 实际影响受多因素调节
- 双字词同音率显著降低(8.19%)
二、同音字家族类型与成员分布的互补格局
- 语言学视角:
- 库藏与使用相对独立
- 静态结构:反映音节库藏(同音字的家族类型和家族成员数)
- 动态使用:体现使用强度(家族使用频率)
- 使用频率的互补性:
- 经济性:鲜明的高频倾向、高频/极高频家族成员的分布优势(尤其是二者中极高频成员的分布优势),使汉语只需要利用一部分音节和其中的少部分成员就能承担绝大部分使用频率,提高了语言使用的效率,
- 多样性:而中频、低频家族类型的存在则为语言使用中必要的词汇多样性和丰富性提供了支撑。
- 库藏与使用相对独立
- 认知心理视角:
- 并行分布式加工模型解释
- 同音聚合的心理实质是由语音吸引子(attractor)所形成的吸引域(basin of attractor)。
- 语音相似会使得词典网络中相应单元的状态在接收输入时发生改变,使其在词典空间中移动、达到一个相对稳定的模式,成为一个吸引子,吸引子周围的区域会逐渐固定,形成吸引域。
- 同音字家族语料的类型多样化和成员经济性的平衡
- 大密度和超大密度家族的作用:
- 例如"yi"这样的音节,有很多同音字
- 形成较大的吸引域
- 当听到类似的音时,更容易被识别出来
- 其中高频字(如"一"、"以")会加强这个吸引域的强度
- 中小密度家族的作用:
- 起到调节作用
- 防止网络过度激活(避免听到所有相似音都联想到高频音节)
- 防止过度规则化(保持音节识别的灵活性)
- 大密度和超大密度家族的作用:
- 并行分布式加工模型解释
并行分布式加工模型 (PDP模型):💡
- 吸引子(attractor):
- 类似于磁铁的作用点
- 在心理词典中,是一个稳定的神经激活模式
- 比如"zhang"这个音,在大脑中形成一个相对稳定的激活模式
- 吸引域(basin of attractor):
- 是吸引子能够影响的范围
- 就像磁铁周围的磁场范围
- 在这个范围内的相似音都会被"吸引"到这个稳定模式
三、同音字家族的幂律分布特点
- 幂律分布的特征:
- 概率密度与变量值成反比
- 呈现重尾分布形态
- 具有"择优连接"特点
- 系统特性:
- 少量中心节点提高效率
- 大量非中心节点保持多样性
- 兼具稳定性与灵活性
- 语言系统的普遍性:
- 符合齐夫规律齐普夫定律
- 体现跨语言共性